

作为长期运营WordPress站点的站长,相信很多人都有过这样的困扰:明明开启了Cloudflare免费CDN,缓存生效后老访客打开速度飞快,但新访客首次访问却慢得离谱,甚至会因为加载超时直接关闭页面。尤其是像主题铺、个人博客、中小电商这类站点,很多都做了桌面端和移动端分离缓存,首次打开卡顿问题更突出,严重影响访客留存和SEO排名。
给大家分享一个真实案例:某站长运营着一个WordPress技术类博客,流量主要来自海外,开启Cloudflare后,国内老访客打开速度稳定在0.3秒,但海外新访客首次访问平均要1.8秒,跳出率高达45%。后来通过缓存预热优化后,海外首次访问速度缩短到0.6秒,跳出率直接下降22%,访客留存率提升明显。
其实,首次访问慢的核心问题,并不是Cloudflare没用,而是源于它的一个底层机制—Cloudflare Worker Cache API是“单数据中心隔离”的。简单来说,就是缓存不共享:如果一个美国纽约的访客触发了缓存,这份缓存只存在于纽约的Cloudflare节点;当英国伦敦的访客第一次访问时,伦敦节点没有这份缓存,就会直接跨洋回你的国内源站(也就是CacheMiss),跨洋传输的延迟加上源站响应时间,速度自然慢到难以接受。哪怕你开了CDN,这种“首次缓存缺失”的问题依然会困扰很多站长。
这里必须重点提醒一句:很多站长会想当然地用Cloudflare Worker访问网站地图,通过自动爬行缓存实现“全站Sitemap遍历预热”,但这种方法在免费版Worker上完全行不通,反而会出问题!
因为免费版Worker有两个致命限制,直接卡死这种方法:
1. 子请求限制(致命伤):每次Worker运行最多只能发起50个外部fetch()请求。普通WordPress站点的html页面+tag标签页面,随便就超过25个,再加上要预热桌面和手机双端,25个网址就会耗尽50次请求,超过限制后Worker直接崩溃报错,预热失败不说,还可能影响网站正常运行。
2. CPU时间限制:免费版Worker只有10毫秒的CPU计算时间,连解析庞大的XML网站地图都不够用,更别说遍历所有页面、完成缓存预热了,大概率会因为CPU超时直接终止运行。
所以,在不花钱的前提下,想高效实现Cloudflare缓存预热,解决首次访问慢的问题,经过主题铺实测,以下3种免费方案最有效,适配绝大多数WordPress站点,不管你是新手站长还是有一定基础,都能轻松上手。
方案1:开启Cloudflare分层缓存(免费!新手首选)
这是最基础、最不用费脑的免费方案,纯后台点击操作,不用写任何代码,开启后就能立竿见影缓解首次访问慢的问题,适合所有用Cloudflare免费版的站长,尤其适合新手。
![图片[1]-Cloudflare缓存预热全教程:解决WordPress首次访问慢,3种免费方案让全站秒开-主题铺](https://cdn.zhutipu.com/wp-content/uploads/2026/03/20260317164639294.png/ztp)
详细操作步骤
- 登录你的Cloudflare后台,找到你需要设置的域名(比如zhutipu.com),进入域名管理主界面。
- 在左侧菜单栏中找到「缓存」选项,点击进入缓存设置页面。
- 在缓存设置页面中,找到「分层缓存(Tiered Cache)」选项,点击右侧的开启按钮。
- 拓扑选择「Smart智能」(系统会自动匹配最优的超级节点布局),无需额外设置,点击保存即可生效。
核心原理
开启分层缓存后,Cloudflare会自动筛选出几个全球核心的“超级节点”作为上层缓存节点,全球300多个边缘节点不再各自单独回源,而是形成一个分层架构。当某个边缘节点(比如伦敦节点)没有目标页面的缓存时,它不会直接跨洋回你的国内源站,而是先向就近的超级节点请求缓存。
这样一来,极大减少了跨洋回源的次数,缩短了首次缓存请求的时间,尤其适合海外流量较多的站点,能快速提升首次访问速度,而且不用占用源站资源,零成本就能优化。
方案2:利用GitHubActions实现全自动免费预热
这是目前最稳、最适合长期运营的免费方案,没有之一。GitHub Actions是完全免费的自动化工具,它的服务器主要部署在美国和欧洲,带宽拉满,而且和Cloudflare边缘节点同地域,请求速度极快,能每隔几小时自动“访问”你的网站,完成桌面端和移动端的双端缓存预热,不用手动操作,一劳永逸。
核心优势
- 完全免费:GitHub Actions对个人和中小站长完全免费,无使用次数和带宽限制。
- 自动化运行:设置好后,每天自动执行预热,不用手动点击,解放双手。
- 双端适配:可同时预热桌面端和移动端缓存,适配分离缓存的站点(比如主题铺)。
- 绕过拦截:脚本自带浏览器伪装和自定义暗号,能轻松绕过Cloudflare的爬虫检测。
详细操作步骤
第一步:准备GitHub账号与仓库
- 如果没有GitHub账号,先免费注册一个(注册流程简单,只需邮箱验证,无需付费)。
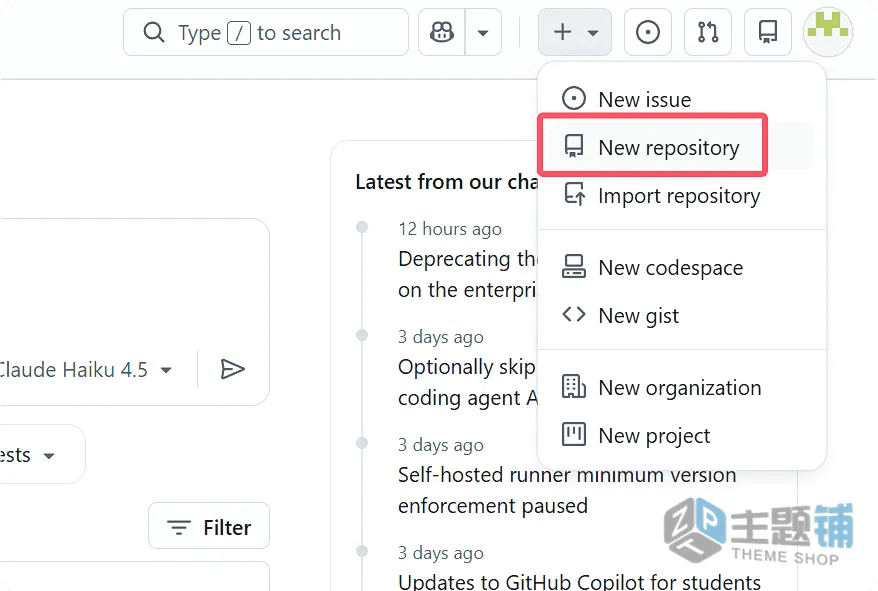
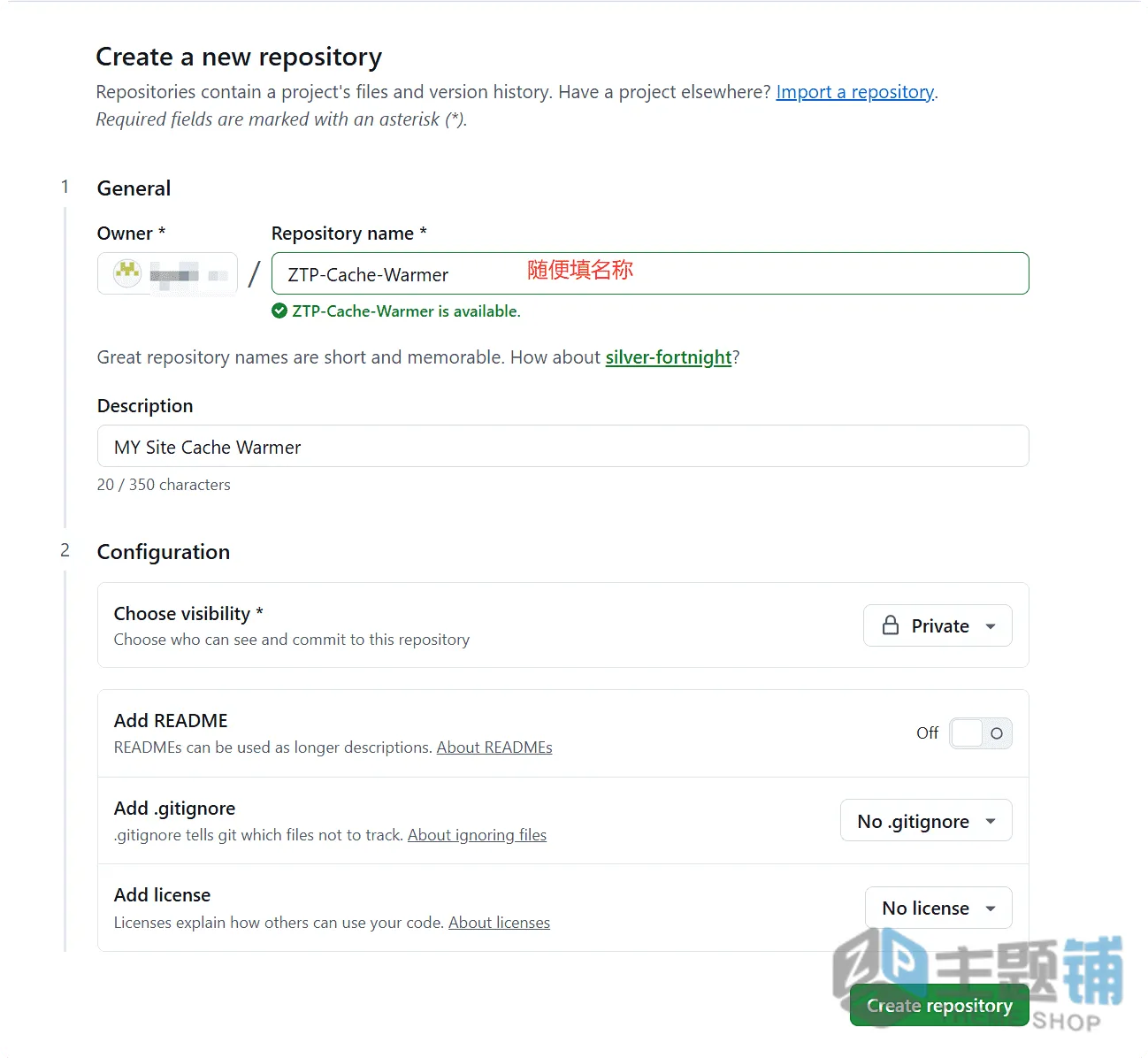
- 登录GitHub账号后,点击右上角的「+」号,选择「新建仓库(Repository)」。

- 仓库名称随便起,比如「Site-Cache-Warmer」,设置为「公开(Public)」(私有仓库也可,不影响使用),点击「创建仓库」即可。


第二步:配置自动化工作流
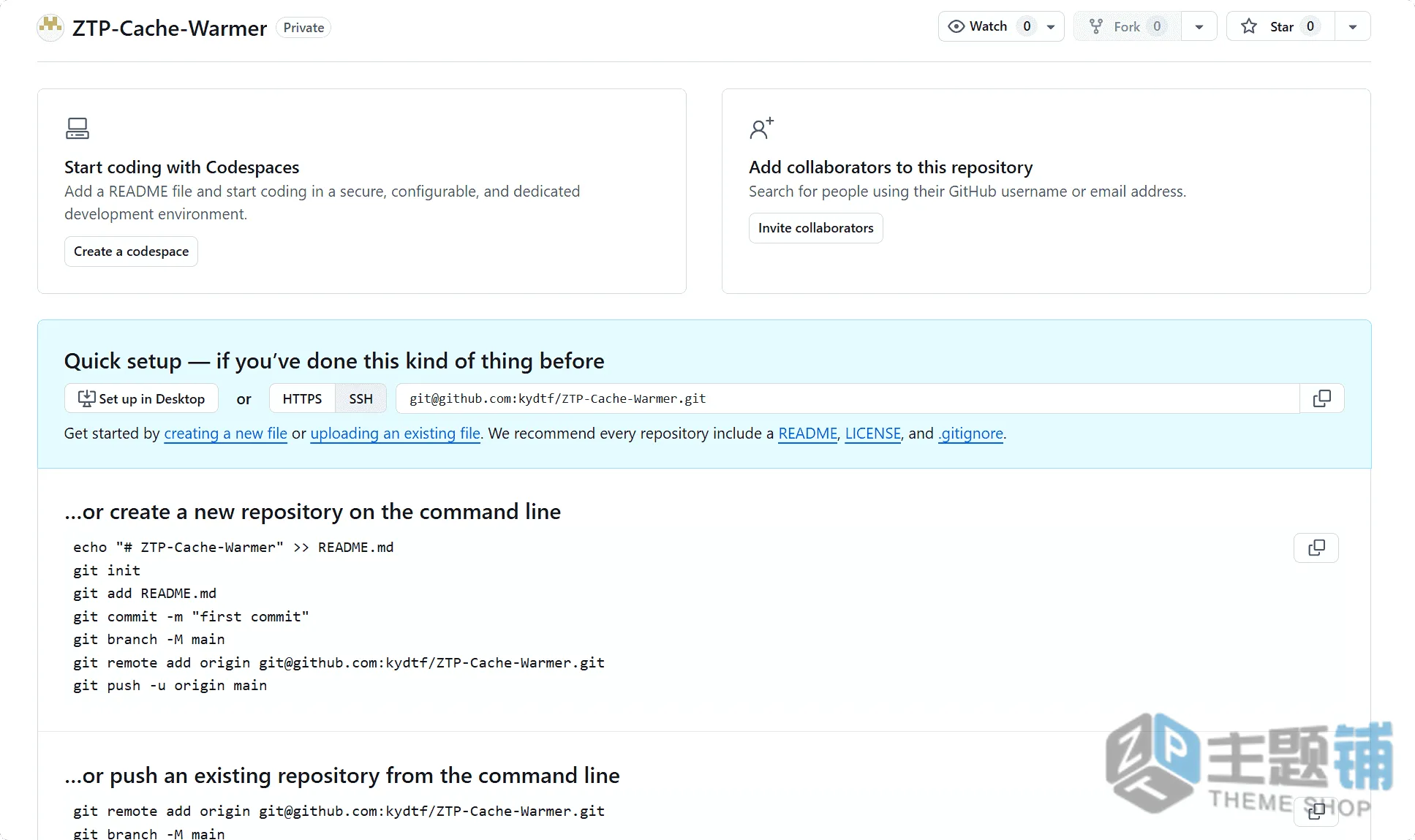
- 进入新建的仓库页面,点击顶部的「Actions」选项卡,再点击「set up a workflow yourself」(手动设置工作流)。

- 删除页面中原本的默认代码,将下面的完整代码复制粘贴进去(重点:必须修改代码中的SITEMAP_URL为你的真实网站地图地址)。

- 点击右上角的「Commit changes」(提交更改),弹出的窗口中,提交信息随便写(比如「初始化缓存预热脚本」),再次点击「Commit changes」,即可保存配置。


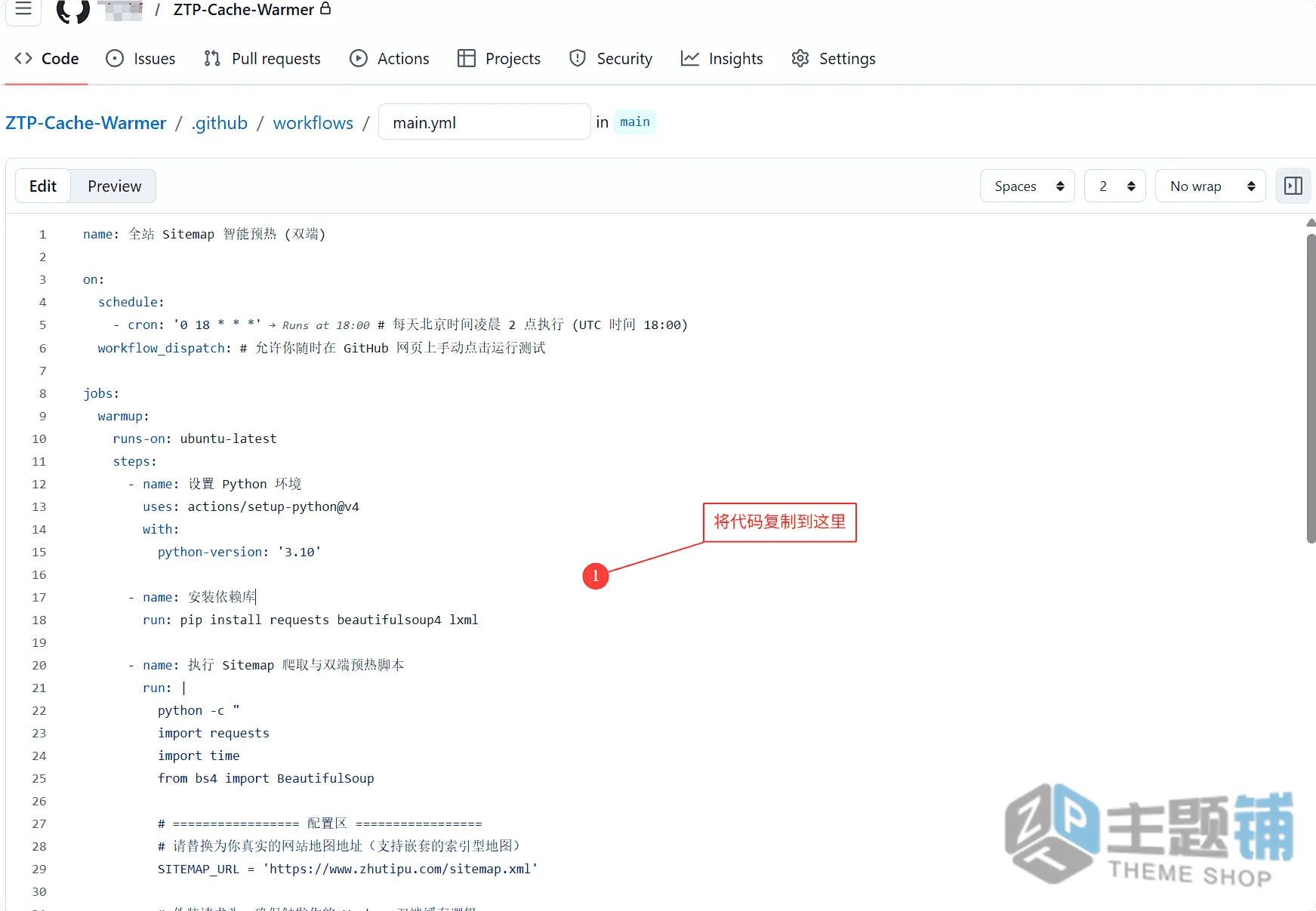
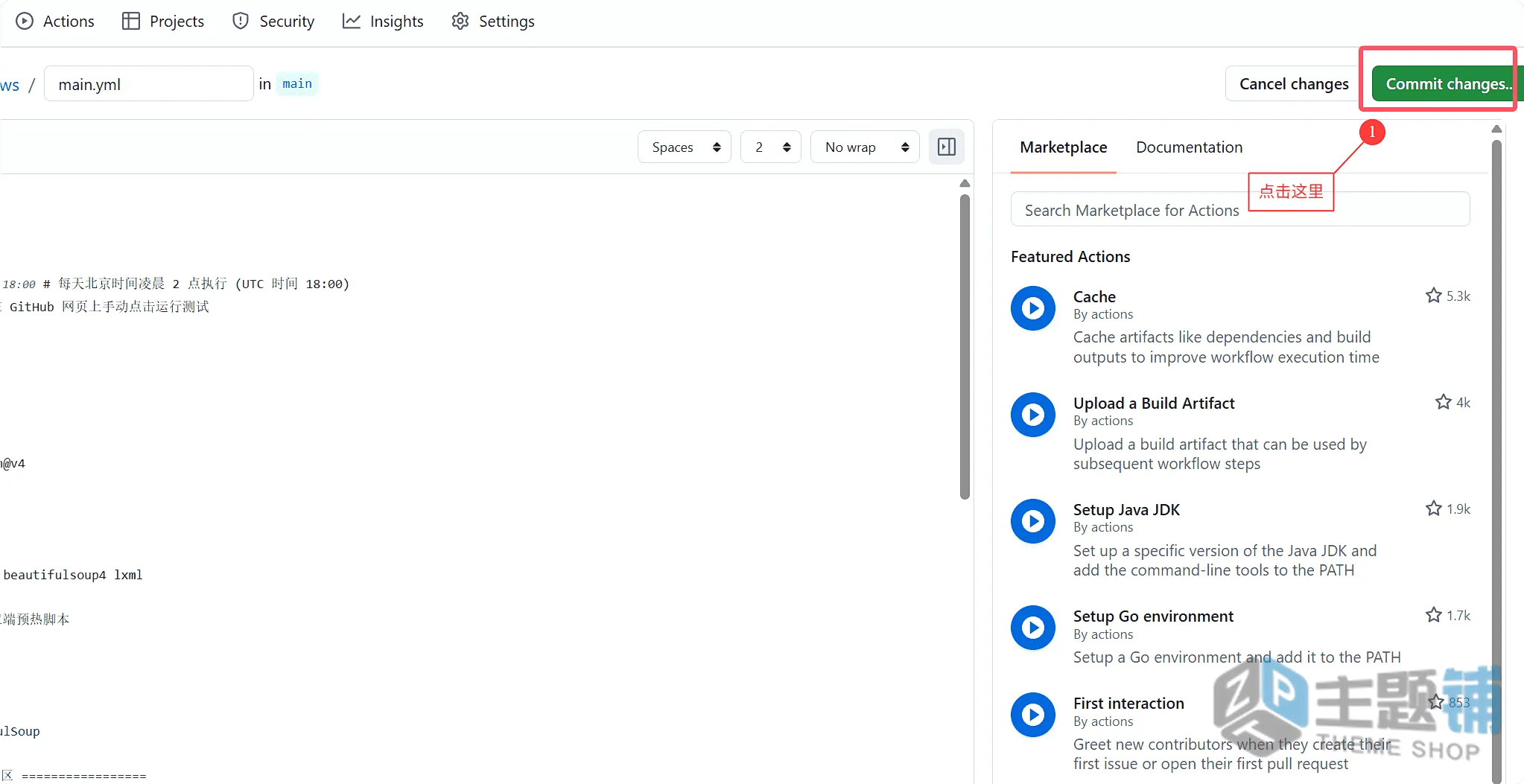
name: 全站Sitemap智能预热(双端)
on:
schedule:
- cron: '0 18 * * *' # 每天北京时间凌晨2点执行(UTC时间18:00)
workflow_dispatch: # 允许你随时在GitHub网页上手动点击运行测试
jobs:
warmup:
runs-on: ubuntu-latest
steps:
- name: 设置Python环境
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: 安装依赖库
run: pip install curl_cffi beautifulsoup4 lxml
- name: 执行Sitemap爬取与双端预热脚本
run: |
python -c "
from curl_cffi import requests
import time
import re
# ================= 配置区 =================
SITEMAP_URL = 'https://www.zhutipu.com/sitemap.xml'
# CF终极暗号(配合WAF跳过规则)
SECRET_HEADER = {'X-Warmer-Key': 'Zhutipu2026_Safe'}
HEADERS_DESKTOP = {'User-Agent': 'Mozilla/5.0 (WindowsNT10.0;Win64;x64) AppleWebKit/537.36 Chrome/114.0.0.0 Safari/537.36'}
HEADERS_DESKTOP.update(SECRET_HEADER)
HEADERS_MOBILE = {'User-Agent': 'Mozilla/5.0 (iPhone;CPUiPhoneOS15_0likeMacOSX) AppleWebKit/605.1.15 Mobile/15E148 Safari/604.1'}
HEADERS_MOBILE.update(SECRET_HEADER)
# ==========================================
def get_urls_from_xml(url):
try:
print(f'正在请求地图: {url}')
# impersonate="chrome110" 完美伪装真实谷歌浏览器的底层特征,直接绕过CF爬虫检测!
r = requests.get(url, headers=HEADERS_DESKTOP, timeout=15, impersonate='chrome110')
if r.status_code != 200:
print(f'⚠️ 警告:请求被拦截!状态码: {r.status_code}')
return[]
locs = re.findall(r'<loc>(.*?)</loc>', r.text)
print(f' -> 成功提取到 {len(locs)} 个链接')
return locs
except Exception as e:
print(f' -> 请求异常: {e}')
return[]
print('【第一步】开始解析总地图...')
initial_urls = get_urls_from_xml(SITEMAP_URL)
if not initial_urls:
print('❌ 未能获取到任何子地图,任务终止。')
exit()
target_urls =[]
print('\n【第二步】开始智能筛选并解析子地图...')
for u in initial_urls:
if u.endswith('.xml'):
if 'post' in u or 'tag' in u:
target_urls.extend(get_urls_from_xml(u))
else:
print(f'⏭️ 智能跳过无关地图: {u}')
else:
target_urls.append(u)
print('\n【第三步】开始清洗目标网址...')
final_urls =[u for u in target_urls if u.endswith('.html') or '/tag/' in u]
final_urls = list(set(final_urls))
print(f'\n✅ 解析彻底完毕!共提取出 {len(final_urls)} 个目标网址等待预热。\n')
if len(final_urls) == 0:
exit()
print('【第四步】启动双端自动预热引擎(每次间隔0.5秒保护源站)...')
success_count = 0
for i, url in enumerate(final_urls):
try:
# 桌面端预热:伪装成Chrome110
r_desk = requests.get(url, headers=HEADERS_DESKTOP, timeout=10, impersonate='chrome110')
# 移动端预热:伪装成苹果Safari
r_mob = requests.get(url, headers=HEADERS_MOBILE, timeout=10, impersonate='safari15_5')
print(f'[{i+1}/{len(final_urls)}] {url} | 桌面:{r_desk.status_code} 移动:{r_mob.status_code}')
if r_desk.status_code == 200 and r_mob.status_code == 200:
success_count += 1
time.sleep(0.5)
except Exception as e:
print(f'[{i+1}/{len(final_urls)}] 预热超时或失败: {url} -> {e}')
print(f'\n🎉 预热任务全部结束!完美预热 {success_count} 个页面。')
"
关键配置修改(必做)
代码中只有「配置区」的2处需要修改,其他内容无需改动,避免出错:
1、SITEMAP_URL:替换成你的网站真实网站地图地址。如果用了SEO插件(比如RankMath、Yoast),通常生成的网站地图地址是sitemap.xml、sitemap_index.xml或wp-sitemap.xml,复制粘贴替换即可。
2、SECRET_HEADER:可以自定义你的专属“暗号”(比如把Zhutipu2026_Safe改成你自己的站点标识),后面配置Cloudflare白名单时会用到,确保和白名单中的值一致。
方案3:终极兜底方案——提升OpenLiteSpeed源站缓存
哪怕你用了上面两种方案,也不可能做到100%的页面提前预热到Cloudflare边缘节点——比如一些发布了几个月的冷门文章、长尾关键词页面,访问量极低,很难被提前预热,依然会出现CacheMiss的情况。
所以,解决“首次访问慢”的终极兜底方案,是提升源站的回源速度。就算Cloudflare没命中缓存,只要你的源站能瞬间吐出数据,访客也不会觉得慢。尤其是用OpenLiteSpeed+LiteSpeedCache插件的站长,这一步必须做,效果立竿见影,而且操作简单。
一般用的是OpenLiteSpeed主机,开启Cloudflare后,冷门文章首次访问回源时间要1.5秒,开启源站爬虫预热后,回源时间直接缩短到0.2秒,哪怕Cloudflare没命中缓存,访客也感觉不到卡顿,跳出率下降了18%。
详细操作步骤(仅适用于OpenLiteSpeed+LiteSpeedCache插件)
- 登录你的WordPress后台,在左侧菜单栏中找到「LiteSpeedCache」插件,点击进入插件设置页面。
- 在插件设置页面中,找到「爬虫(Crawler)」选项卡,点击进入。
- 找到「启用爬虫」选项,点击开启,无需额外复杂配置,保存设置即可(默认设置已足够满足大多数站点需求)。
![图片[2]-Cloudflare缓存预热全教程:解决WordPress首次访问慢,3种免费方案让全站秒开-主题铺](https://cdn.zhutipu.com/wp-content/uploads/2026/03/20260317170102956.png/ztp)
核心原理与效果
开启LiteSpeed的源站预热爬虫后,你的国内服务器会在“闲时”(比如凌晨访问量最低的时候)自动爬取网站所有页面,将其生成纯静态HTML文件,存储在服务器的内存或硬盘中。
当Cloudflare发生CacheMiss,跨洋回源到国内时,OpenLiteSpeed不需要再去查询MySQL数据库,也不需要执行PHP代码,直接把硬盘里的静态HTML文件快速返回给Cloudflare。实测下来,回源时间能从原来的1~2秒,瞬间缩短到200毫秒以内,仅剩网络传输的物理延迟,哪怕是冷门页面,也能实现快速响应,彻底解决兜底的回源慢问题。
补充:GitHubActions预热的手动触发与日志查看
很多站长设置好自动化预热后,想立即测试效果,不用等每天凌晨2点——因为我们在脚本开头添加了「workflow_dispatch」配置,允许你随时手动触发预热任务,快速测试是否生效。
手动触发步骤
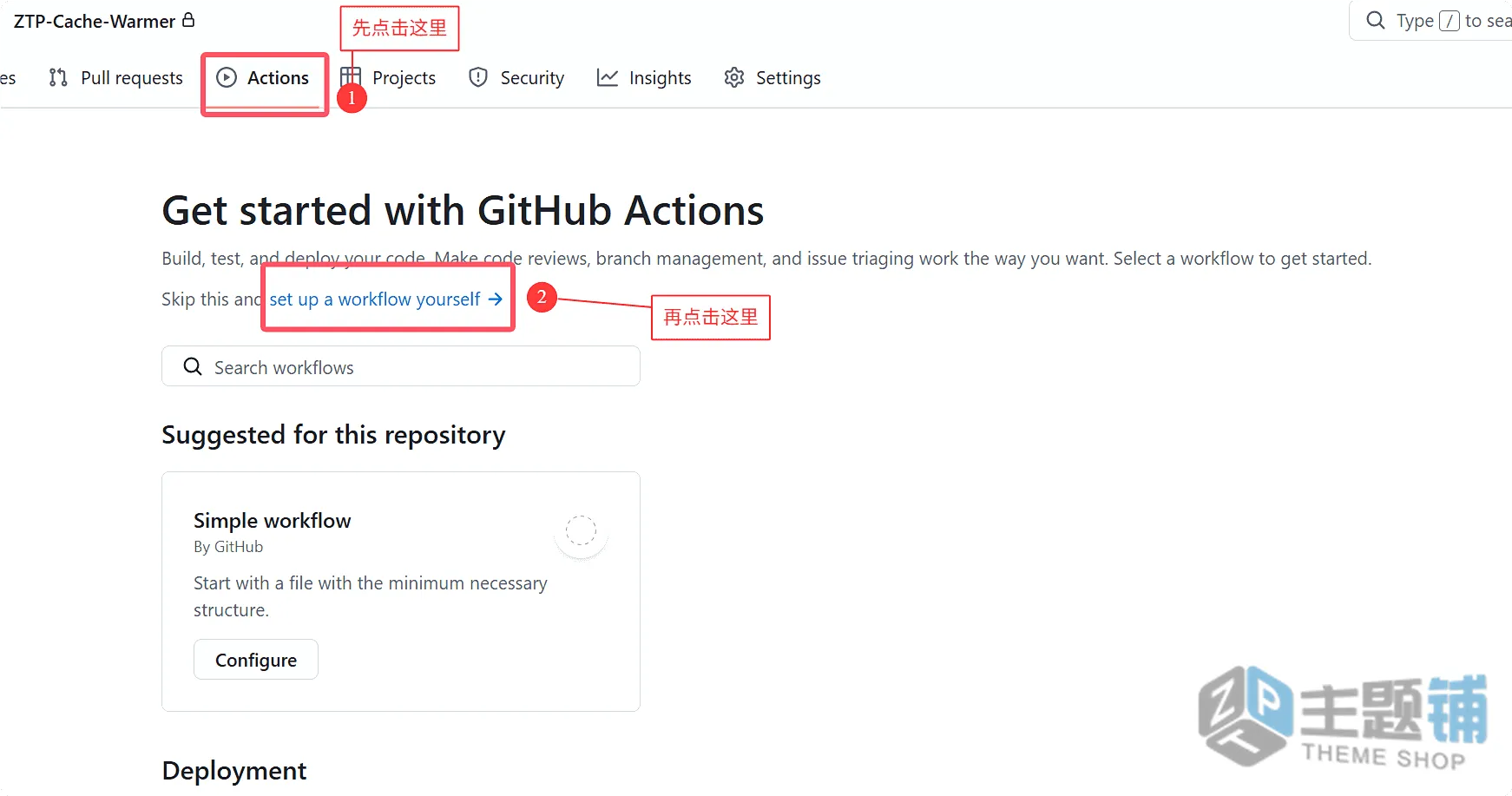
- 打开你的GitHub仓库,点击顶部的「Actions」选项卡。
- 在左侧菜单中,找到「全站Sitemap智能预热(双端)」,点击进入该工作流页面。

- 在页面右侧,会看到一个灰色的「Run workflow」按钮,点击它,再点击弹出的绿色「Run workflow」按钮,预热任务就会立即开始执行。

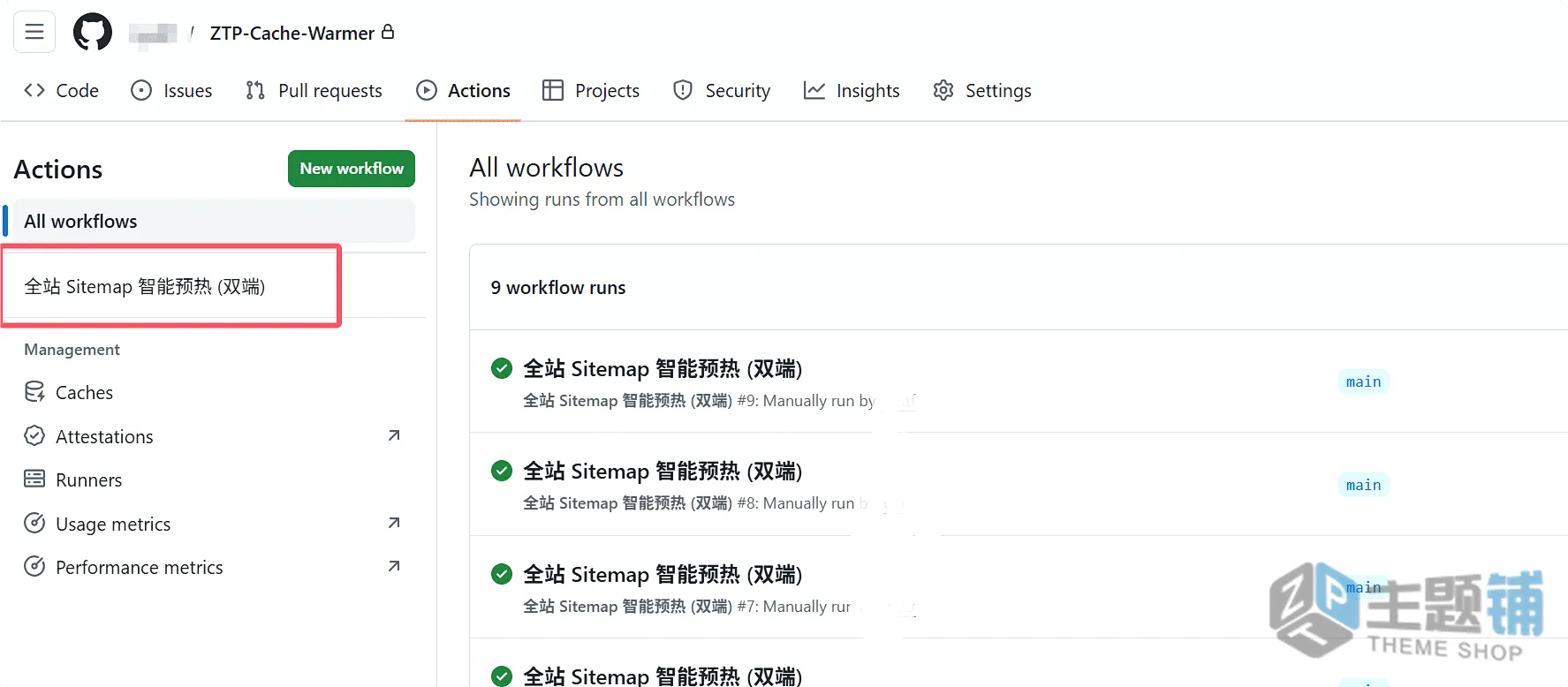

查看运行结果(判断是否成功)
- 触发任务后,页面会自动刷新,看到一个黄色的转圈图标,说明任务正在运行。
- 点击这个黄色转圈的任务,进入任务详情页,再点击「warmup」这个Job(任务)。
- 展开「执行Sitemap爬取与双端预热脚本」这一步,就能看到详细的运行日志——日志会一行行显示正在爬取的网址、桌面端和移动端的请求状态码,如果状态码是200,说明预热成功;如果是403,说明被Cloudflare拦截,需要设置白名单。
![图片[3]-Cloudflare缓存预热全教程:解决WordPress首次访问慢,3种免费方案让全站秒开-主题铺](https://cdn.zhutipu.com/wp-content/uploads/2026/03/20260317170103981.png/ztp)
补充:Cloudflare白名单设置与关闭自动程序攻击模式(必做)
很多站长测试时会发现,GitHub Actions的请求被Cloudflare拦截(日志显示403状态码),哪怕设置了WAF跳过规则也没用——这是因为Cloudflare免费版有一个霸道的开关,会无视所有自定义跳过规则,必须手动关闭。
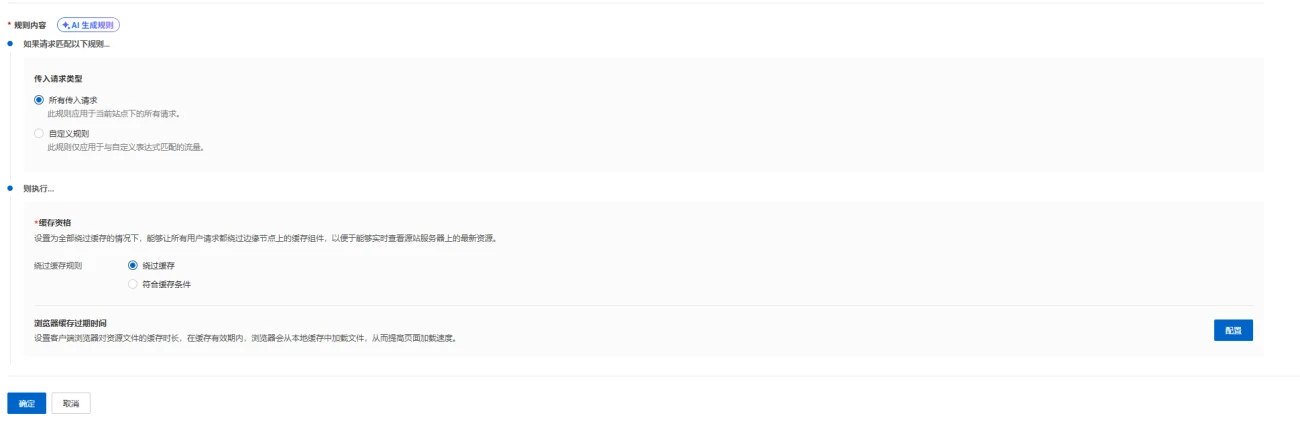
第一步:设置WAF自定义白名单(给预热请求开“免死金牌”)
- 登录Cloudflare控制台,进入你需要设置的域名(比如zhutipu.com)。
- 左侧菜单栏点击「安全性(Security)」→「WAF」,切换到「自定义规则(Custom rules)」选项卡。
- 点击右侧蓝色的「创建规则(Create rule)」按钮,开始设置白名单规则。
- 规则名称:随便写,比如「Allow-GitHub-Warmer」,方便后续识别。
- 如果匹配:点击「编辑表达式(Edit expression)」,切换到手动输入模式,粘贴以下内容(注意替换暗号为你脚本中设置的内容): http.request.headers[“x-warmer-key”] eq “Zhutipu2026_Safe” (如果不用手动模式,可直接选择:字段=HTTP Header,Header名称=x-warmer-key,运算符=等于,值=你脚本中设置的暗号)

- 选择操作:下拉菜单选择「跳过(Skip)」,然后勾选以下需要跳过的安全功能(为了确保绝对不拦截,全勾上最稳妥):
- 所有剩余自定义规则
- 安全级别
- 超级机器人防御模式(这是拦截爬虫的元凶,必须跳过)
- WAF托管规则

- 点击右下角的「部署(Deploy)」按钮,白名单规则立即生效。


第二步:关闭自动程序攻击模式(BotFightMode)(关键!)
这一步是很多站长容易忽略的,也是请求被拦截的核心原因——Cloudflare免费版的「自动程序攻击模式」非常霸道,只要开启,就会无视你设置的任何WAF自定义跳过规则。
GitHub Actions的服务器全部部署在微软Azure(AS8075)数据中心,Cloudflare的自动程序攻击模式会默认拦截这类数据中心的请求,哪怕你伪装了浏览器、加了暗号,也会被直接拦截。
![图片[4]-Cloudflare缓存预热全教程:解决WordPress首次访问慢,3种免费方案让全站秒开-主题铺](https://cdn.zhutipu.com/wp-content/uploads/2026/03/20260317170104390.png/ztp)
操作步骤
- 进入Cloudflare域名后台,点击左侧「安全性」→「机器人」选项卡。
- 找到「自动程序攻击模式(BotFightMode)」选项,点击关闭即可。
常见疑问:关闭这个模式危险吗?
完全不危险!关闭自动程序攻击模式后,我们已经通过WAF自定义规则设置了白名单,只允许带有专属暗号的请求跳过拦截,其他恶意爬虫依然会被Cloudflare的基础防护拦截。而且手动设置的自定义规则,比默认的自动程序攻击模式更灵活、更精准,能更好地保护网站。
总结:3种方案适配场景与注意事项
本文详细讲解了Cloudflare缓存预热的3种免费方案,结合真实站长案例,从操作步骤、核心原理到注意事项,全方位解决WordPress站点首次访问慢的问题,帮助站长提升访客留存和网站体验。
3种方案的适配场景,大家可以根据自己的情况选择,建议优先组合使用,效果最佳:
- 方案1(分层缓存):所有用Cloudflare免费版的站长必开,零成本、操作简单,快速缓解首次访问慢问题。
- 方案2(GitHubActions全自动预热):适合有海外流量、需要长期运营的站点,自动化程度高,双端预热,缓存命中率提升最明显。
- 方案3(OpenLiteSpeed源站缓存):用OpenLiteSpeed主机的站长必做,作为兜底方案,解决冷门页面回源慢的问题。
最后提醒大家:缓存预热不是一劳永逸的,建议定期查看GitHub Actions的运行日志,确保预热任务正常执行;同时,当网站发布新文章、更新页面后,可手动触发一次预热,让新页面快速被Cloudflare缓存,进一步提升访问速度。按照本文的教程操作,绝大多数WordPress站点的首次访问速度都能提升50%以上,彻底摆脱“CDN开了也慢”的困扰。











暂无评论内容